Не так давно был написан пост, в котором я изложил свои соображения о применимости запросов на естественном языке (NLQA) в ECM-системах. Главная мысль состоит в следующем: поиск информации через запросы на естественном языке по критериям – достаточно неэффективное занятие, сценарии нужно рассматривать шире, а проблему глубже. Ниже поясню, на основе чего были сделаны такие выводы.
Перед моей небольшой группой стояла задача сделать прототип так называемого умного поиска в рамках конкретной ECM системы. Стояла цель научить систему выдавать результаты по поисковым запросам пользователей, сделанным на естественном языке.
Чтобы понять, что ищут люди, было проведено небольшое исследование, где мы опросили людей и проанализировали их поисковые запросы. Результатом анализа стал набор шаблонов, покрывающий большинство поисковых сценариев опрошенных людей. Все они, так или иначе, отвечают на вопросы: «какие объекты найти» и «кто, что и когда делал с объектом (документом, папкой, workflow item и т.п.)». Обнаружилось, что в запросах могут фигурировать имена сотрудников или названия организаций, в качестве временных интервалов используются такие нечеткие понятия, как «недавно», «на прошлой неделе», «в этом году» и т.п.
Для распознавания русскоязычных запросов мы применили готовый парсер Tomita, реализованный Яндексом в виде свободной программы. Tomita позволяет на внутреннем программном языке определить шаблоны для выделения структурированной информации из текста. В итоге, например, из поискового запроса на естественном языке «какие документы вчера редактировал Иванов Иван» Tomita извлекает следующие факты: ищем – документы, время – вчера (dd.mm.yyyy), операция – редактирование, субъект операции – Иванов Иван.
Мы подготовили несколько десятков шаблонов и встроили «умный поиск» в систему.
Что можно найти, используя «умный поиск»? Ниже представлен ряд примеров.
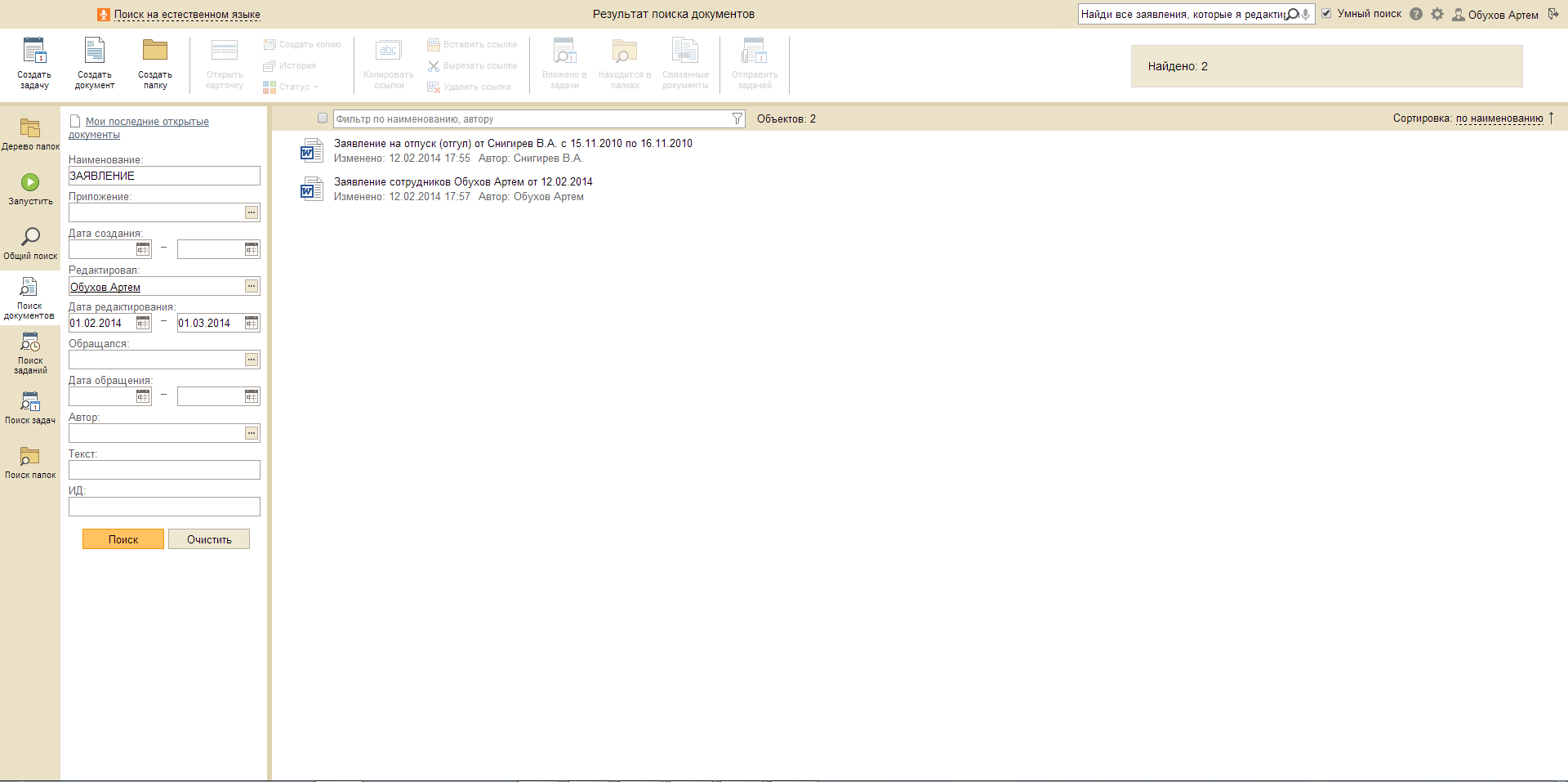
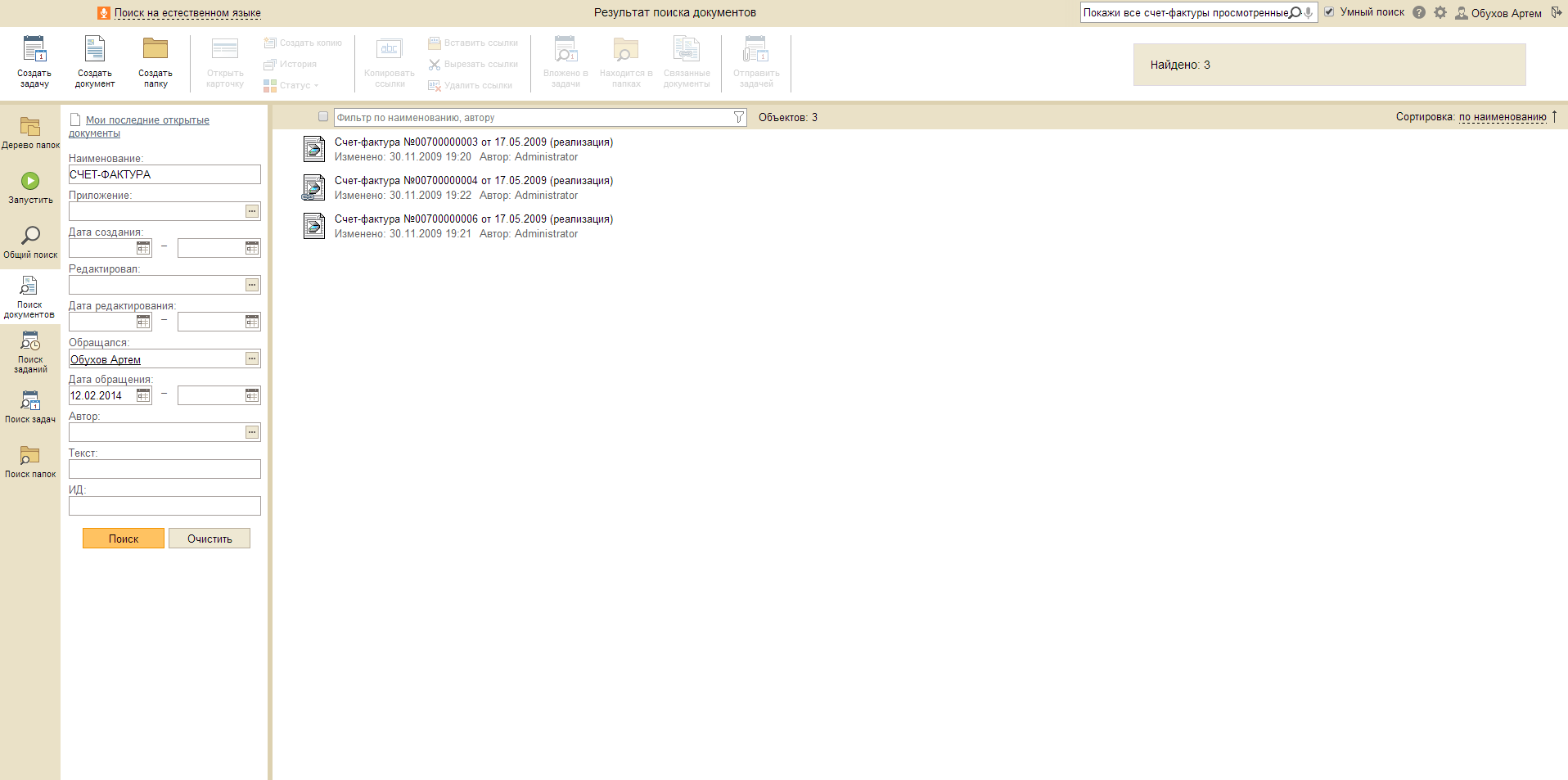
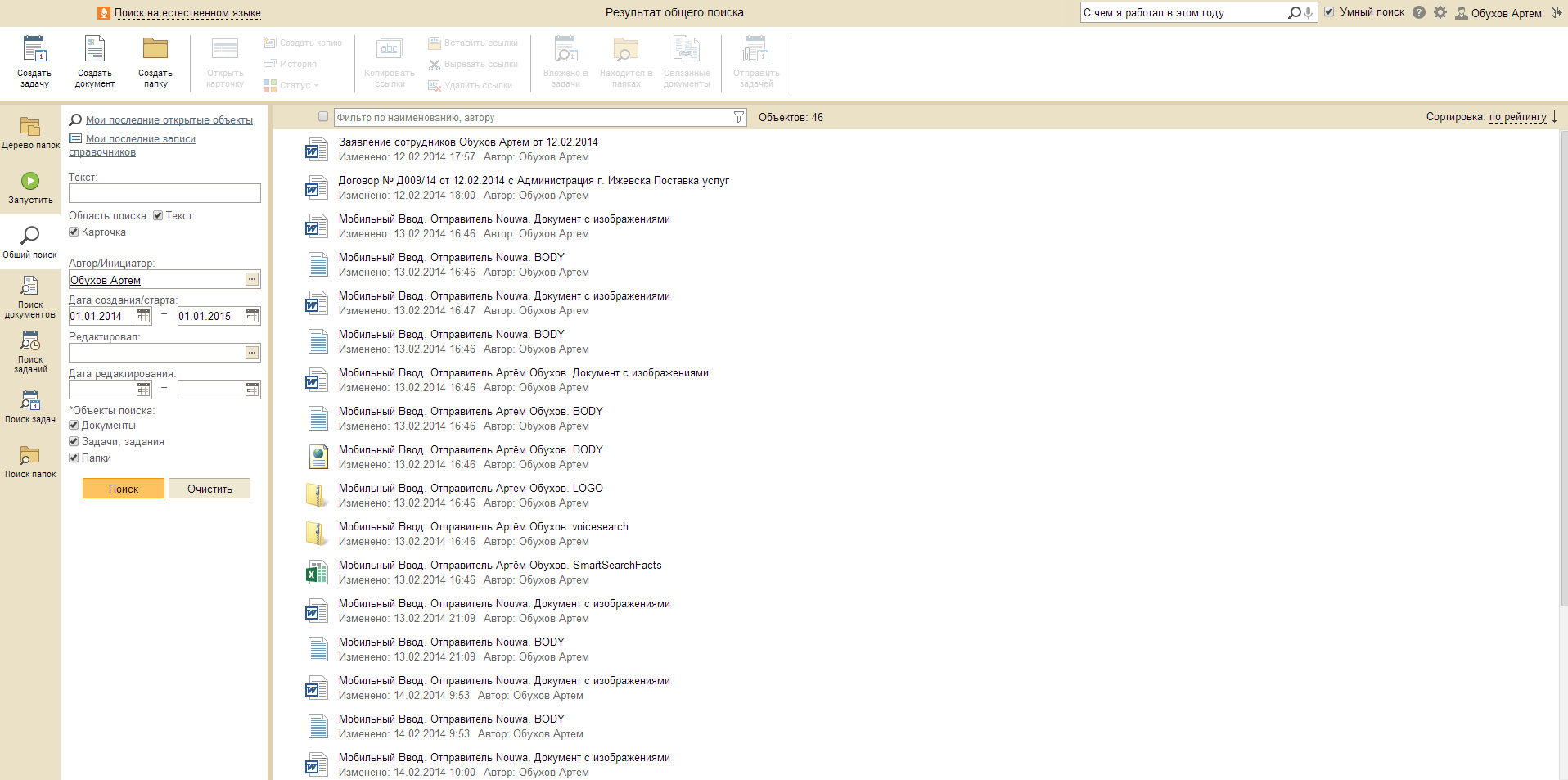
Запрос: Найди все заявления, которые я редактировал в этом месяце.
Запрос: Покажи все счет-фактуры, просмотренные мной 12 февраля.
Запрос: С чем я работал в этом году.
В целом распознаются такие запросы, как:
Найди мне все договорные документы, которые я редактировал на прошлой неделе.
Все заявления отдела маркетинга за февраль.
Мои недавние созданные документы.
Задачи, инициированные Обуховым Артемом в прошлом месяце.
Объекты, с которыми я недавно работал.
Покажи все входящие письма просмотренные мной 17 июля.
Найти задания, отмененные Сидоровым в 1998 году.
С чем я вчера работал.
Найти документы содержащие заказы автомобилей.
Найти созданные мной папки с задачами.
Выдать папки с заданиями, с которыми я работал год назад.
И т.д.
Решение прошло опытную эксплуатацию в реальных «боевых» условиях, и сейчас видно, что у него есть ряд проблем: технических и «сценарных», пользовательских.
Технические проблемы связаны с некачественным распознаванием имен сотрудников и организаций (учет падежей и т.п.). С этим можно бороться, вводя и наполняя словари.
Гораздо хуже проблемы сценарные.
Пользователю сложно вводить так много текста. Если применять голосовой ввод (что тоже было опробовано), то получаем, во-первых, дополнительные технические проблемы с качеством распознавания, а во-вторых, сложно представить себе человека, разговаривающего с настольным компьютером всерьез. Это было бы, возможно, более естественно при работе с небольшим мобильным устройством, где клавиатурный ввод затруднен, но это еще следует подтверждать опытным путем.
Пользователь не знает, какие запросы он вообще может формировать. Увы, количество шаблонов пока недостаточно, чтобы распознать все возможные запросы. Пока пользователю явно удобнее вводить критерии искомых документов в удобную поисковую форму: и быстрее, и все критерии перед глазами.
Если и применять «умный поиск», то к запросам менее формальным и более смысловым, ориентированным на содержание документов. Например, «найти все договоры по закупке оргтехники за прошлый месяц» или «в каком протоколе заседаний мы касались вопроса уборки мусора в парке». Увы, это пока нереально.
Думаю, основной вывод в том, что в таком виде умный поиск пока слабо применим. Впрочем, если вам видны какие-то задачи, где он реально полезен, или есть мысли, как подобный NLQA-механизм можно было бы усовершенствовать, я готов это обсудить!
Позиция России в рейтинге Всемирного банка Doing Business
является основным индикатором эффективности работы Минэкономразвития – в 2013
г. наша страна поднялась в нем на 6 пунктов, до 112-го места. Но это только
начало пути: в указе президента «О долгосрочной государственной экономической
политике» установлены конкретные цели – рост до 50-й позиции в 2015 году и до
20-й в 2018 году.
По оценкам экспертов, доля госзаказа составляет 15-20% от
совокупного объема ИКТ-рынка России, и в ближайшее время объемы госзаказа будут
продолжать расти за счет целого ряда крупных инициатив.
Во-первых, это все инициативы, направленные на создание
электронного государства, – Единый портал госуслуг (ЕПГУ) и перевод госуслуг в
электронную форму, инфраструктура электронного правительства, СМЭВ, МФЦ.
Во-вторых, это работы по информатизации здравоохранения.
В-третьих, внедрение УЭК как первый шаг на пути к
электронному паспорту гражданина.
Среди наиболее значимых государственных инициатив можно
отметить также пакет ИТ-проектов, связанных с введением единой контрактной
системы, проект перехода на межведомственный безбумажный документооборот
федеральных органов исполнительной власти к 2017 г., а также создание
национальных технологических платформ – национальной программной платформы
(НПП) и национальной суперкомпьютерной технологической платформы (НСТП).
∙ Какие госинициативы определяют развитие ИКТ в госсекторе?
∙ Каковы результаты информатизации госсектора на сегодняшний
день?
∙ Каковы прогнозы развития ИКТ в госсекторе?
∙ Какие технологии могут дать наибольшую отдачу в повышении
работы госаппарата
∙ Каковы основные проблемы и пути их решения в
информатизации регионов
∙ Международный опыт в информатизации в госсекторе
Эти и многие другие вопросы будут рассмотрены в рамках конференции
«ИКТ в госсекторе 2014».
На данный момент подтвердили выступления с докладами:
● Максим Казак, Главный редактор CNews;
● Сергей Гуральников, Заместитель руководителя
Федерального казначейства;
● Роман Ивакин, директор Департамента информационных
технологий и связи Министерства здравоохранения РФ;
● Татьяна Матвеева, Начальник Управления
информационных технологий ФНС России;
● Эдуард Лысенко, Директр департамента информатизации
и связи Ярославской области;