Рассылка закрыта
Вы можете найти рассылки сходной тематики в Каталоге рассылок.
Запись блога "Преимущества и сложности обучения пользователей ECM-систем с помощью видеороликов" от Крестина Извекова
|
||||||||||||||||||||||||||||||||||||||||||||||

 Обучение с помощью роликов – подход все более популярный. Многие порталы, те же
Обучение с помощью роликов – подход все более популярный. Многие порталы, те же 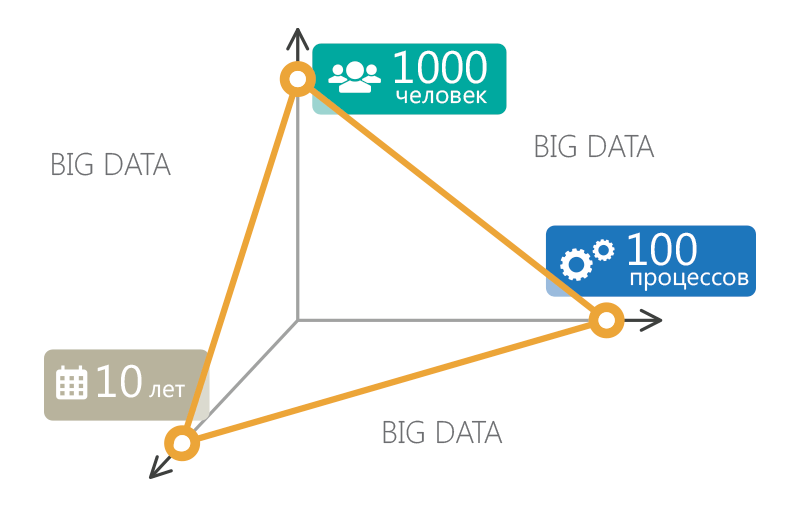

| В избранное | ||

Вы можете найти рассылки сходной тематики в Каталоге рассылок.
|
||||||||||||||||||||||||||||||||||||||||||||||
| В избранное | ||