Достаточно часто случается так, что затраты на хостинг проекта больше, чем все прочие расходы на его содержание. Особенно это касается тех проектов, которые активно используют Amazon AWS. Но далеко не все знают, что Amazon предоставляет различные средства для того, чтобы позволить своим клиентам платить за пользование сервисами AWS меньше.
Что такое Auto Scaling и как он работает
Auto Scaling — это технология от Amazon, которая позволяет увеличивать/уменьшать количество твоих инстансов в EC2 в зависимости от заданных тобой условий: нагрузки на инстансы, объема трафика и прочего. Таким образом, ты всегда сможешь быть уверен в том, что твой проект будет продолжать свою работу даже при резком росте трафика, а в случае минимального количества посетителей ни один цент не будет потрачен впустую на оплату неиспользуемых мощностей.
Итак, основные преимущества использования Auto Scaling заключаются в следующем:
Меньше вреда от некорректно работающего инстанса. Auto Scaling может определять неисправный инстанс, удалять его и запускать новый на замену удаленному.
Схема работы проекта будет более отказоустойчивой. Auto Scaling можно сконфигурировать на использование нескольких подсетей или Availability Zones. Таким образом, если одна подсеть или Availability Zone станет недоступна, Auto Scaling начнет создавать инстансы в другой для того, чтобы проект был доступен извне.
Увеличение и уменьшение количества используемых инстансов по мере необходимости. Немаловажен тот факт, что плата за использование Auto Scaling не взимается, ты платишь лишь за те инстансы EC2, которые были запущены.
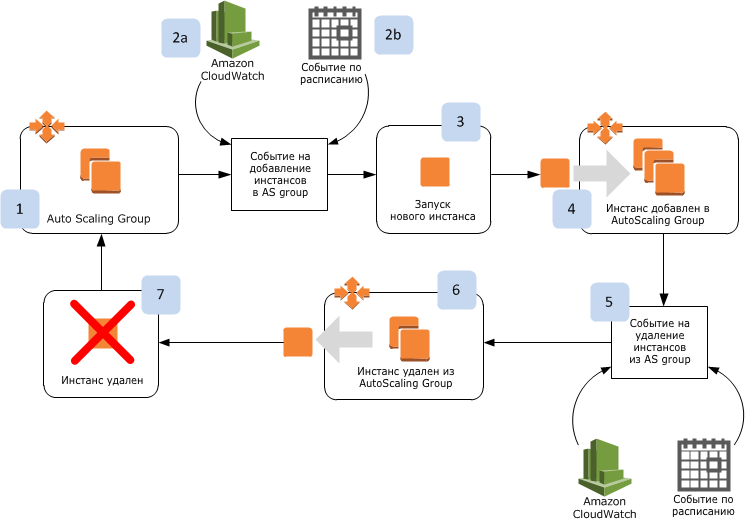
Как вообще работает Auto Scaling? Типовой пример изображен на рисунке.
Пример Auto Scaling
Мы начинаем с Auto Scaling Group, у которой желаемое количество инстансов выставлено в 2. Происходит событие на добавление инстансов в Auto Scaling Group. В рамках этого события Auto Scaling получает инструкции на запуск нового инстанса. Данное событие может либо быть запланированным согласно расписанию, либо возникать по результатам срабатываний CloudWatch-событий. После этого новый инстанс создается, конфигурируется и добавляется в Auto Scaling Group. Процедура инициации удаления инстанса происходит точно так же — она срабатывает либо по расписанию, либо на основе метрик CloudWatch.
Углубление в детали
С услугой Auto Scaling тесно связаны такие три понятия, как Groups, Launch Configurations и Scaling Plans. Разберем их подробнее.
В Auto Scaling Groups объединяются инстансы, выполняющие одинаковые функции (например, только www-инстансы или только MySQL) с целью управления ими и увеличением/уменьшением их количества. То есть если твоему приложению для достижения максимальной производительности необходимо увеличить количество инстансов того или иного типа, это делается в настройках соответствующей Auto Scaling группы. Ты можешь делать это вручную, а можешь задать некоторый набор условий, согласно которым инстансы будут добавляться/удаляться, и тогда количество запущенных инстансов будет регулироваться автоматически. Как уже упоминалось выше, Auto Scaling умеет проверять «здоровье» каждого инстанса. Если, по мнению Auto Scaling, инстанс из какой-либо Auto Scaling группы окажется «нездоров», то он будет уничтожен и будет создан новый инстанс ему на замену.
Launch Configuration — это совокупность параметров (таких как ID образа, тип инстанса, SSH-ключи, группы безопасности и маппинг блочных устройств), однозначно описывающих конфигурацию инстанса, который необходимо создавать при использовании данной Launch Configuration. Когда ты создаешь Auto Scaling группу, тебе необходимо связать ее с одной из существующих Launch Configuration. Достаточно важный момент: Launch Configuration нельзя изменять после создания. То есть если тебе необходимы новые инстансы с какими-то новыми параметрами (например, переделанный AMI), то необходимо создать новую Launch Configuration. После чего ты указываешь новую Launch Configuration в настройках Auto Scaling группы, и новые инстансы будут создаваться с новыми настройками. Старые инстансы изменены не будут.
А с помощью Scaling Plan можно указать Auto Scaling, при каких условиях нужно создавать дополнительные инстансы / удалять лишние существующие.
Использование Auto Scaling
Не стоит думать, будто использование Auto Scaling для проекта — это еще один шаг в сторону увольнения штатного системного администратора :). На самом деле есть и специфичные для Auto Scaling’a проблемы. Вот часть из тех, с которыми мы столкнулись:
Чересчур долгие периоды удаления старых записей из ARP-кеша у тех инстансов, которые взаимодействуют с Auto Scaling инстансами. Значения по умолчанию были для нас слишком велики. Выражалось это в итоге вот в чем: Auto Scaling инстанс с IP 10.0.1.100 был удален двадцать минут назад. В ARP-кеше на MySQL-сервере осталась запись, где IP 10.0.1.100 однозначно привязан к некоторому MAC-адресу. Пять минут назад был создан новый Auto Scaling инстанс с IP 10.0.1.100, но с другим MAC-адресом. Догадываешься, что получилось в итоге? Правильно, из-за того, что ARP-кеш на MySQL-сервере своевременно не обновился, у нас отсутствовала связь между www и MySQL — так как с MySQL-сервера пакеты уходили на старый MAC-адрес. Решилось это правкой настроек, уменьшением тайм-аутов на очистку ARP-кеша, но ситуация все равно была неприятная.
Время создания автоскейлов должно быть минимальным. В этом очень сильно помогает создание Launch Configuration на базе преконфигуренного AMI. Из нашей практики: на достаточно крупных проектах имеет смысл создавать AMI, которые будут содержать не только соответствующим образом настроенное ПО, но и последнюю ревизию кода. Это позволит Auto Scaling инстансу принимать и обрабатывать запросы от посетителей буквально сразу же после загрузки операционной системы. Если же время создания автоскейла достаточно велико и занимает порядка пяти-десяти минут, то это может негативно сказаться на производительности проекта. Особенно когда только что стартовала рекламная кампания клиента, которая дала поток посетителей, втрое превышающий норму на этот день недели и это время.
Точная настройка условий, при которых будет создан новый Auto Scaling инстанс. В первое время работы с Amazon Auto Scaling мы столкнулись с проблемой: выяснялось, что созданные нами условия, по которым Amazon определял необходимость создания новых автоскейлов, хоть и выглядят верными, но на самом деле далеки от реальности. Мы не учитывали, сколько времени уходит на создание одного инстанса, за какое время нагрузка на существующие инстансы прыгала от «выше среднего» до «сверхвысокая», и еще некоторые мелкие детали. В результате — шлифовка корректных условий для Auto Scaling заняла у нас несколько дней.
Эти проблемы были самыми основными. Порой случаются мелкие, но досадные казусы, например, недавно не сразу смогли собрать новый AMI с некоторыми изменениями из-за проблем на стороне API Amazon, что задержало выкладку новой версии продукта в production.
При использовании Auto Scaling достаточно важным остается такой момент, как мониторинг всего и вся на созданных автоскейлах. Причем крайне важно, чтобы инстансы подключались к мониторингу автоматически сразу после создания: при высоких величинах посещаемости проекта за день может быть создано/удалено порядка нескольких десятков автоскейлов, добавлять их все в мониторинг вручную будет сложновато. Мониторинг важен по одной простой причине: периодически новый автоскейл создается некорректно. Код отрабатывает с ошибками, коннекты по нужным адресам не проходят. В таких ситуациях сразу после обнаружения подобных инстансов необходимо исключить их из Load Balanсer’a для того, чтобы запросы посетителей не отправлялись на них.
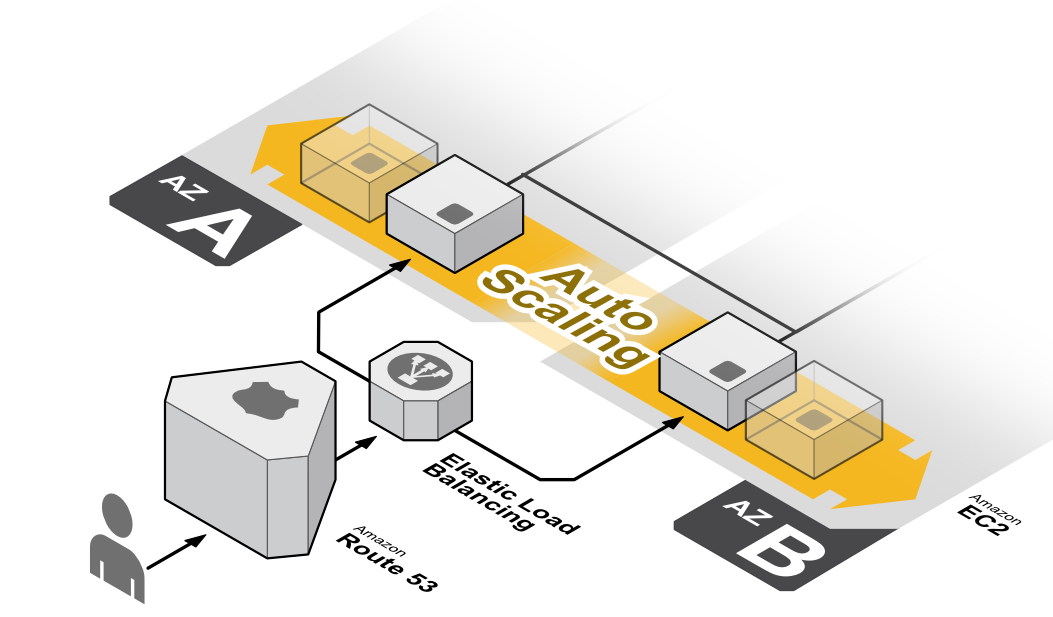
Типовая схема применения Auto Scaling
Как выглядит обычный проект, чья инфраструктура полностью состоит из сервисов Amazon? В качестве DNS-серверов для основных доменов используется Amazon Route 53. Это отказоустойчивый DNS-сервер от Amazon, который обладает очень полезными функциями. Все инстансы общаются между собой только по внутренним IP-адресам, чтобы трафик ходил только внутри дата-центров Amazon. Инстансы с MySQL, memcached, Redis, MongoDB и прочими — обычного типа. Инстансы, на которых выполняется код проекта (обрабатываются запросы посетителей), состоят в Auto Scaling группе. При различных изменениях величины входящего трафика от пользователей проекта соответствующим образом меняется и количество www-автоскейлов, что позволяет выдерживать любую нагрузку.
Заключение
Автоматизация работы системного администратора всегда была актуальной задачей. Сначала это были bash-скрипты, потом уровень вырос до применения инструментов, автоматизирующих настройку серверов, таких как Puppet/Chef/CfEngine, сейчас же появляется новый уровень — автоматизация управления железом серверов.
Да, в данном случае железо виртуальное, но сейчас есть возможность создания виртуальных серверов, которые могут быть мощнее, чем многие из существующих физических. Amazon Auto Scaling — яркий пример технологии, которая позволяет в автоматизированном режиме управлять количеством серверов, задействованных в работе вашего проекта, с помощью достаточно удобного и гибкого интерфейса. Также не стоит забывать, что именно с помощью Auto Scaling ваша организация сможет сэкономить тысячи долларов на оплате хостинга проекта — это тоже достаточно немаловажный фактор.
До встречи! Увидимся, когда будем разговаривать еще об одной технологии, помогающей сделать нашу жизнь лучше :).
Сегодня мы хотели бы рассказать тебе об одном из самых веселых типов уязвимостей, которые встречаются в современных приложениях, — ошибках логики. Прелесть их заключается в том, что при своей простоте они могут нести колоссальный ущерб вплоть до полного захвата сервера и, что немаловажно, с большим трудом определяются автоматизированными средствами.
Но чтобы не грузить тебя определениями, которые более-менее очевидны и которые можно найти на тех же OWASP и CWE, перейдем сразу к делу.
Классика жанра
Для начала рассмотрим «лабораторный пример» — представим себе, что мы совершаем покупки в магазине, в котором при оформлении заказа передаются три параметра: ID товара, количество товара (quantity) и цена (price). Другими словами, запрос будет выглядеть следующим образом:
В случае если цена никак не валидируется (хотя зачем вообще ее передавать таким способом?), атакующий имеет возможность подменить ее значение и купить пару пылесосов по цене в 1 доллар. «Ха, кто же так делает?» — спросишь ты и будешь неправ: уязвимости подобного рода (ошибки бизнес-логики) встречаются в трех из пяти реальных проектов крупных заказчиков, включая европейских, аудиты для которых мы регулярно проводим.
К той же серии неверного использования параметров, заложенных, вероятно, еще на стадии проектирования, относится и следующий баг:
Как ты наверняка успел заметить, в данном случае атакующий имеет возможность восстановить произвольный пароль на свою почту, причем данный параметр был оставлен разработчиками как «пасхалка» с комментарием remove this. И это в крупной финансовой организации!
Twitter big fish
Для полноты картины: подобные фейлы встречаются и у монстров наподобие Twitter. В числе одной из уязвимостей, зарепорченных нами от лица @defconmoscow, был следующий запрос:
POST /ajax/send_product_email HTTP/1.1
Host: about.twitter.com
...
email=VICTIM_EMAIL&language=][&download_link=HERE_COMES_SPOOFED_LINK&device=][&atc_product_download=twt_atc_mpp&utm_source=][&utm_medium=][&utm_term=&utm_content=&utm_campaign=][&form_build_id=][&form_id=][
Поскольку урл в параметре download_link не проверялся, было возможно организовать рассылку от лица Твиттера с предложением скачать мобильное приложение по указанной злоумышленником ссылке. Профит!
Немного классификации
Помимо «проблемных параметров», мы выделили следующие разделы, каждый из которых содержит в себе описание и примеры уязвимостей:
прямое обращение к функционалу;
незащищенные страницы;
проверки на стороне клиента;
ошибки многопоточности.
Давай рассмотрим их по порядку.
Прямое обращение к функционалу
Одна из самых веселых ошибок авторизации/бизнес-логики — функционал, доступ к которому открывается только после авторизации, но который при этом доступен и без авторизации. Первый пример — крупнейшая австрийская страховая компания (здесь и далее названия компаний не указываются по NDA и морально-этическим соображениям).
Вероятно, разработчики их веб-приложения решили привлечь новых клиентов, интегрировав в него различного рода дополнительный функционал, доступный в социальных сетях и уже привычный для многих: поделиться новостью с друзьями или быстро авторизоваться через учетную запись социальной сети. Однако использование такого рода «плюшек» может оказаться совсем не столь безобидным, как это кажется. Ниже представлена реализация механизма авторизации на сайте этой компании, использующая для аутентификации пользователя учетную запись в Facebook:
Как видно из кода, единственное, что требуется для авторизации на сайте, — это вызвать функцию loginUserFB с FB-токеном, который может быть получен любым, кто знает страницу жертвы на Facebook (например, с помощью findmyfacebookid.com). Другими словами, если мы знаем человека, зарегистрированного на данном сайте через его FB-аккаунт, мы можем получить полный доступ к его учетной записи без ввода каких-либо паролей или ответа на секретные вопросы.
Но это еще не все: так как не все пользователи авторизуются через Facebook, то в таблице со списком зарегистрированных аккаунтов вместо токенов у части пользователей будут проставлены нули.
Таким образом, передав вместо токена 0, мы сразу же получаем доступ к первому по списку пользователю из таблицы USERS. Аналог данной таблицы представлен на рис. 1.
Рис. 1. Данные таблицы USERS
В данном случае это была учетная запись администратора системы, имеющая доступ к панели администрирования сайта. Позже именно через эту панель с помощью формы загрузки изображений на сайт был успешно залит шелл и получен полный доступ к целевой машине.
Еще один пример из жизни — неавторизованный доступ к API. Следующий запрос позволял получить данные о транзакции пользователя (включая идентификатор, время, сумму и другую информацию) обычным GET-запросом: /api/transactions/[id].
Рис. 2. Данные о транзакции
Что забавнее, добавление/обновление пользовательских данных осуществляется стандартным PUT-запросом и по-прежнему без авторизации! Оставим читателю пространство для воображения, что можно сделать в этом случае :).
Еще один пример — приложение российских государственных структур. В данном случае логика разработчиков была направлена именно на обеспечение безопасности и надежности системы — они решили удалять старые или уже не используемые в веб-приложении картинки и аватарки пользователей для высвобождения места и предотвращения DoS-атак.
Однако по каким-то причинам функционал удаления был выделен в отдельную процедуру deletephoto, которая в качестве аргумента принимала путь к удаляемому файлу, да еще и с полными правами для любого, в том числе и незарегистрированного, пользователя!
Вот так выглядел GET-запрос для удаления аватарки пользователя с ID 1773: /edit/upload/index.php?mode=deletephoto&filename=/1773/profile739.jpg Только этот факт позволил удалять с сервера веб-приложения фотографии и остальные данные, загружаемые другими пользователями, включая их аватарки и материалы, используемые в статьях и заметках.
Но это еще не все. Очень скоро выяснилось, что для параметра с путем к файлу не была реализована фильтрация входных данных на path traversal, то есть в качестве аргумента можно было передать путь к файлу, находящемуся в корневой директории:
В результате стало возможным удалить файлы index.html и .htaccess из корневой папки с веб-контентом, что позволило получить листинг всего содержимого этой директории.
Рис. 3. Листинг содержимого директории с веб-контентом
Именно эта уязвимость в дальнейшем позволила найти в одной из поддиректорий файлы, содержащие персональные данные зарегистрированных там пользователей.
Незащищенные страницы
Еще один тип логических уязвимостей и уязвимостей авторизации — незащищенные страницы. Как и в случае с предыдущим разделом, зачастую статичные страницы, страницы без референсных ссылок и прочее, попадающее под описание information disclosure, часто может быть проэксплуатировано, что приведет к катастрофическим последствиям. Следующие два примера показывают, как подобные вещи, а именно невнимательность и непридание значения таким страницам позволили довести раскрытие информации до RCE. Первый пример — крупная корейская медицинская организация. Данные пользователя надежно защищены, на страницах минимум динамики, повышения привилегий не предвидится, в общем, на первый взгляд все печально. Единственное, что привлекает внимание, — при создании карточки пользователя есть функционал загрузки фотографий. Нет, залить шелл через него не удалось — как следует из комментариев на HTML-странице, это «улучшенная версия загрузчика». Оттуда же следует, что неулучшенная версия все еще доступна в папке photo_uploader. Неавторизованный доступ к ней, уязвимость при проверке расширения фото и пренебрежение принципом минимальных привилегий — и через шестьдесят секунд имеем рут.
Рис. 4. Root-доступ к серверу медицинской организации
Таким образом, один комментарий на странице данных авторизованного пользователя приводит к тому, что произвольный неавторизованный злоумышленник может за один вечер выгрузить все данные о пациентах. Boo! Более длинная цепочка уязвимостей, которая привела к схожему результату, была проведена нами в еще одном значимом для государства веб-приложении. Все началось с тестирования функционала отправки фидбэков…
Любой, даже незарегистрированный пользователь мог отправить фидбэк модератору сайта. Сообщение отправлялось через POST-запрос (рис. 5), в котором помимо тела сообщения, имени и email отправителя можно было передать и файл.
Рис. 5. POST-запрос, отправляемый на сервер для отсылки фидбэка модератору с возможностью передачи в нем файла
Но в ответ возвращалось лишь сухое «Спасибо! Ваше сообщение отправлено». Это не просто не позволяло узнать, куда и с каким именем этот файл был сохранен, но даже наводило на мысль, что все сообщение — это обычное письмо с аттачем, отправляемое на почту модератору. Потому особого профита в этой форме мы не усмотрели и продолжили тестировать остальной функционал.
На том же сайте работала система сбора статистики и мониторинга Piwik (рис. 6). Большинство настроек в ней были выставлены по умолчанию, включая активный гостевой аккаунт, который позволял любому пользователю сайта получить подробную статистику о том, кто, когда и какие именно страницы сайта посещал. Конечно, данные об IP-адресах и датах посещения пользователями сайта интересны, но самым ценным здесь был список посещенных другими пользователями внутренних страниц сайта, включая раздел модератора. Несмотря на отсутствие доступа к этому разделу, в паре страниц, вероятно добавленных уже после передачи сайта в эксплуатацию, данная проверка все же отсутствовала, и, как результат, они и весь функционал на них были доступны любому, кто знал об их существовании.
Рис. 6. Piwik. Ссылка на незащищенную страницу модерации, посещенную ранее модератором или администратором сайта
Именно там, в форме поиска пользователя по имени, нами и была найдена SQL-инъекция, от которой был очень хорошо защищен весь пользовательский функционал по умолчанию. Поскольку права внутри БД были лимитированы и работать с файловой системой через эту инъекцию было нельзя, мы сдампили всю базу и начали изучать ее на факт наличия каких-либо конфигурационных данных, паролей или другой информации, позволявшей продолжить атаку и захватить весь сервер. Тут и была найдена таблица feedback, содержащая все отправленные нами сообщения, имена пользователей, отправивших их, и… имена к файлам, которые все же сохранялись в директории с веб-контентом, да еще и с тем же расширением, которое было указано в поле filename POST-запроса (рис. 7)!
Рис. 7. Запись в таблице feedback с именем файла, отправленного на сервер вместе с фидбэком пользователя
Каких-то пара минут, и однострочный шелл уже на сервере в файле, хоть и с рандомным именем, но с заветным расширением php:
Уверен, дорогой читатель, тебе не составит труда понять, что за команда была выполнена и какой результат мы получили на рис. 8.
Рис. 8. Исполнение кода на целевом сервере через загруженный шелл
Проверки на стороне клиента
Один из самых частых паттернов логических уязвимостей — проверки на стороне клиента. Другими словами, фильтры на клиентской стороне не позволяют ввести/изменить определенные данные, но при этом сервер не проводит никакой дополнительной валидации. Классический пример — нередактируемые поля в банковских переводах. Рис. 9 отображает результат успешного обхода таких проверок: в одном случае (банк top-3 Австрии) существовала возможность создания транзакций, когда у лимитированного пользователя такая возможность не подразумевалась, в другом (банк top-10 России) — возможность изменения нередактируемых полей и подмены номера счета в переводах.
Рис. 9. Обход клиентских проверок в банках
Тем не менее это тоже не все — одна известная в Европе страховая организация решила использовать в качестве основной защиты критически важного функционала JavaScript. Речь идет не об XSS (хотя куда уж без них), но о доступе к админке. Если неавторизованный пользователь пытается обратиться к защищенной админской странице /manage/environment/administrator/, скрипт проверяет валидность таких намерений и либо пропускает пользователя, либо отправляет на страницу логина. Честно говоря, поскольку использование NoScript у меня стоит по умолчанию, я был весьма удивлен, увидев таблицу с данными пользователей, и лишь после просмотра кода страницы обнаружил эту чудесную фичу. Если упростить, проверка валидности обращения к странице выглядит следующим образом:
<script language=javascript>
sure = confirm('Are you admin?');
if (sure)
location.href='/manage/index.jsp';
else
history.back();
</script>
Ошибки многопоточности
Наконец, еще один тип ошибок логики из нашего рейтинга — ошибки более низкого уровня абстракции — состояние гонки (Race Condition). Состояние гонки — «ошибка проектирования многопоточной системы или приложения, при которой работа системы или приложения зависит от того, в каком порядке выполняются части кода» (с). Другими словами, если, например, два потока одновременно получают доступ к данным на запись, результат может быть непредсказуемым. Так и случилось с одной крупной британской платежкой — для получения доступа к данным невезучего пользователя понадобилось… обновить страницу! Начав разбираться, мы поняли, что проблема в механизме генерации сессии — при неудачной авторизации и определенном стечении обстоятельств сессия пользователя выставлялась в null и не менялась при следующем успешном логине. Соответственно, написав простенький скрипт, который обращался к главной странице с данными пользователя с нулевой сессией, мы за один вечер сграббили восемь аккаунтов с суммарным счетом более 50K долларов. Более подробно об этом ты можешь прочитать в презентации.
Summary
Как ты видишь, приведенные примеры не являются чем-то запредельно сложным — достаточно просто поверить в закон вселенского фейла :). При этом критичность найденных уязвимостей позволяла в ряде случаев залить шелл и получить полный контроль над приложением/сервером и всегда несла в себе ощутимый финансовый и репутационный ущерб для организации. Дерзай! Но соблюдай закон!