Рассылка закрыта
При закрытии подписчики были переданы в рассылку "Очевидное-Невероятное" на которую и рекомендуем вам подписаться.
Вы можете найти рассылки сходной тематики в Каталоге рассылок.
Технические фантазии в реальном воплощении No 54
| Информационный Канал Subscribe.Ru |
Код tech.tft
Выпуск No 54
Автор и ведущий Cesiy
Деревни и села в Раменском районе Московской области
Country & village in Ramenskoye district Moscow region
(Анализ в отношении к русскому языку)
Введение.
1.
Прочитайте их :
Агашкино Аксеново Амирово Антоново Апариха
Аргуново Аринино Бахтеево Белозериха
Бельково Бисерово Большое Ивановское Боршева Бояркино Бритово Бубново Булгаково
Быково Василево Васильево Верея Вертячево
Верхнее Велино Верхнее Мячково Вишняково Владимировка Власово Воловое Володино
Вороново Воскресенское Вохринка Вялки Галушино
Ганусово Гжель Глебово Головино Григорово Давыдово
Дементьево Денежниково Денисьево Дергаево Донино Дор Дурниха ДьяковоЕганово
Ждановское Жирово Жирошкино Жуково Заболотье
Забусово Заворово Загорново Залесье Заозерье Запрудное Захариха Захарово
Зеленая Слобода Зюзино ИвановкаИгнатьево Игумново
Ильинское Каменное Тяжино Капустино Карпово
Клишева Колоколово Коломино Колупаево Константиново Коняшино Копнино Коробово
Костино Косякино Кочетовка Кочина Гора Кошерово Кратово Кривцы Кузнецово
Кузяево Кукузево Кулаково Лаптево
Левино Липкино Литвиново Локтевая Лубнинка Лужки Лысцево Макаровка
Малахово Малое Саврасово Малышево Марково Меткомелино Мещеры Минино Митьково
Михайловская Слобода Михеево Михнево МорозовоНадеждино
Натальино Нащекино Нестерово Нижнее Велино Нижнее Мячково Никитское Никоновское
Никулино Новое Новомайково Новомарьинка Новохаритоново
Обухово Овчинкино Осеченки ОстровцыПанино
Паткино Патрикеево Первомайка Першино Пестовка Петровское Пласкинино Плетениха
Подберезное Поддубье Полушкино Поповка Починки Прудки Пушкино
Редькино Речицы Рогачево Родники Рыбаки Рыболово
Рылеево Салтыково Сафоново Сельцо Семеновское
Сидорово Сильвачево Синьково Слободино Слободка Соломыково Софьино Спас-Михнево
Становое Старково Старниково Старомайково Степановское Строкино Татаринцево
Тимонино Титово Толмачево Торопово Трошково Турыгино Тяжино
Ульянино Устиновка Федино
Фенино Фомино Фоминское Фрязино Хлыново
Холуденево ХрипаньЧулково Шевлягино
Шилово Ширяево Шмеленки Шувайлово ЩеголевоЮрасово
Юрово Юсупово Яньшино
Как видно, имеется
приоритет в названиях деревень с окончанием на «во» и «но». Например, Дергаево,
Власово, Донино. Также как и Косино или Выхино.
Все они собраны вместе,
вы их теперь видите и читаете. Вам интересно, потому что они Ваши, или
Вы в них, может быть, живете. Рядом с Вами, естественно, много «соседей».
Теперь Вы точно знаете, что деревень в районе много – около 200. Такое
большое число. Оно отражает насыщенность района деревнями и, соответственно,
людьми в них.
2.
3.
Рассматривая список,
можно заметить, что названиями «занят» почти весь алфавит, а количество
названий на каждую букву разное. Так накопилось исстари. Те, кто эти названия
давал, не предполагали их сортировать, и вовсе об этом не думали. И хорошо,
что так сделали. Они, эти «старинные» люди, давшие названия, непроизвольно
отразили (озвучили) русскую историю. Озвучили и незаметно для себя соединили,
собрали все их так, как мы их сейчас видим. В общем, со временем сложилось
как бы само по себе. Почему так получилось?
Вероятно, в результате
исследования это можно понять.
Названия деревень и сел, собранные в этом списке, можно показать по-иному, чтобы лучше их себе представить. Чтобы они были бы лучше показаны относительно друг друга. И в отношении к русскому алфавиту. Это изображено графически, см. рис.1. На нем по горизонтальной оси последовательно отложены буквы алфавита, а по вертикальной – количество названий на каждую букву. Получился целый «лес» линий, в котором как пики торчат «деревья». Так распределились названия.
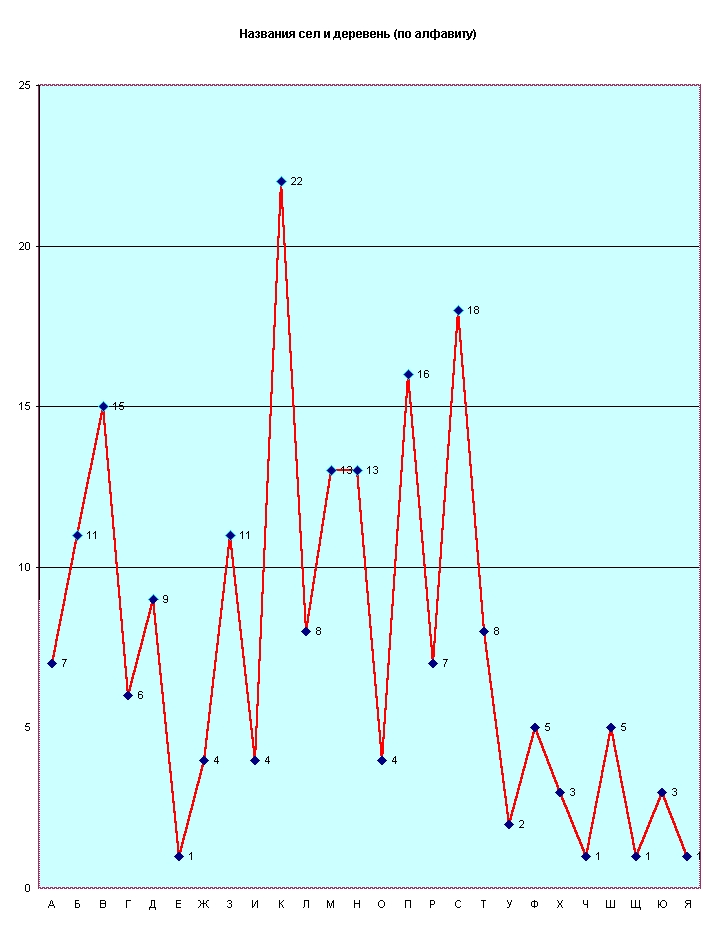
На какую-то одну букву названий «собрано» меньше, на другую – больше, иногда существенно больше. Как видно, лидируют слова и названия на букву «К», их 22 – среди них, такие как Клишева, Коняшино, Косякино, Кошерово, Кузяево. Наоборот, на буквы «Е», «Ч», «Щ», «Я» – их только по одному: Еганово, Чулково, Щеголево, Яньшино. Берегите их. Теперь мы об этом знаем, хотя, может быть, это представление было и раньше. Эти названия оригинальны и о чем-то говорят. О чем?!
Всматриваясь в график
по рис.1, можно «найти» и многое другое, а можно и не найти, как пожелаете.
Он – сухой, в нем почти все получилось абстрактно: ломаная линия
с устремленными вверх острыми пиками. На остриях – цифры. Они показывают
уровень названий, т.е. число имеющихся деревень относительно каждой
буквы. По горизонтальной оси, под буквами эти цифры повторены, – еще более
сухо. Общее число, их сумма, как говорилось ранее, 200.
Рассматривать такой «лес»
с пиками "деревьев" не очень удобно, хотя каждый определит это сам. Так
уж составлена последовательность русского алфавита, названия по нему распределяются
неравномерно. В чем причина?
4.
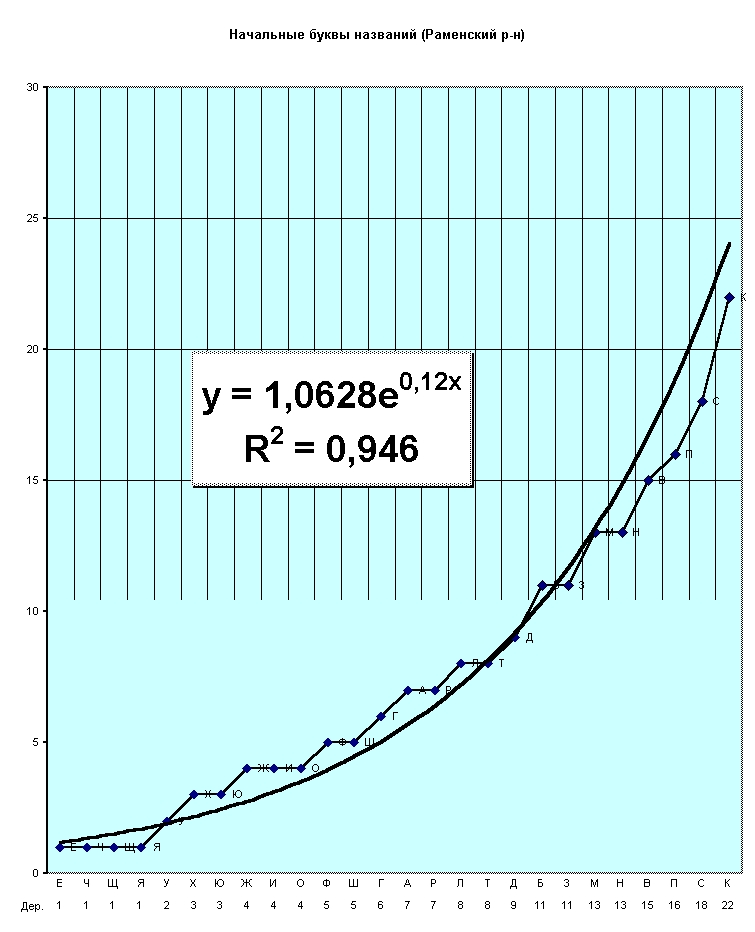
Строим тренд – график
математической функции, которая отражает общую тенденцию изменения ряда
данных. В результате получаем ее величество ЭКСПОНЕНТУ!
Вот те раз!
Наши предки, не зная математики
и не думая об этом, «собрали» экспоненту названий. Дали им не только
скрытое «экспоненциальное» звучание, но и внутренний смысл. До сих пор
он не был проявлен.
Посмотрите на нее!
На экспоненту! Она красиво, близко и плавно проходит по всем названиям
деревень, отображает их. Или наоборот? - они отображают ее?!
5.
Коэффициент, равный
0,12
– замечательный коэффициент. Он – как бы «наш» земляк. Интересно, что в
стихах Пушкина – если, например, также найти «его» экспоненту – он
равен 0,13! Он (этот коэффициент)
был определен, например, по его стихотворению «ПРИЗНАНИЕ». Значит, Пушкин-поэт
близок нам еще по одному признаку. Или, наоборот, - мы ему близки
самобытностью языка и названий деревень.
В обоих случаях коэффициент
достоверности (R) в формулах экспонент достаточно высокий, – примерно
0,95 – предел мечтаний.
Вот так сложилось у нас в прошлом. Как видите, там много чего еще можно открыть. Эти “открытия” в данном случае показывают не только родное, но и музыкальное, и математическое звучание русского языка. Перед Вами был представлен маленький этюд или штрих нашей истории. В новом изложении. Может быть, было интересно.
В Вашем районе может быть по-другому. Проверьте! Совсем это не сложно, при этом будет выявлен исторический (и современный) штрих ранее назначенного состояния. Это рядом с нами. Что-то, может быть, будет ещё ближе.
Ваш Cs_55 (по Менделееву).
Ведущий и автор Cesiy
Архив Рассылки
![]()
http://subscribe.ru/
E-mail: ask@subscribe.ru
Отписаться
Убрать рекламу
| В избранное | ||
