| ← Октябрь 2007 → | ||||||
|
1
|
2
|
3
|
4
|
5
|
7
|
|
|---|---|---|---|---|---|---|
|
8
|
9
|
10
|
11
|
12
|
14
|
|
|
15
|
16
|
17
|
18
|
19
|
21
|
|
|
22
|
23
|
24
|
25
|
26
|
28
|
|
|
29
|
30
|
31
|
||||
За последние 60 дней ни разу не выходила
Сайт рассылки:
http://www.sql-ex.ru
Открыта:
15-09-2004
Статистика
0 за неделю
Новости сайта "Упражнения по SQL" (http://www.sql-ex.ru) 159
Новости сайта "Упражнения по SQL (http://www.sql-ex.ru)" Выпуск 159 (13 октября 2007 г.)Новым посетителям сайтаМы надеемся, что справочного материала сайта окажется достаточно для самостоятельного обучения. Кроме того, свои решения вы можете обсудить на форуме сайта. Опытных же специалистов приглашаем проверить (продемонстрировать) свое мастерство и принять участие в соревновании, обеспечиваемом рейтинговой системой учета времени выполнения заданий. Фактически, рейтинг ведется на втором этапе тестирования, который начинается сейчас после решения 57-ти задач первого этапа. При подсчете рейтинга каждого участника отбрасывается один самый худший показатель среди всех решенных им упражнений. Демонстрация плана выполнения запроса и сравнительная оценка эффективности решений поможет вам освоить принципы оптимизации запросов, которые пригодятся на третьем рейтинговом этапе, который начинается после 138 задачи.Имеется возможность получить сертификат по SQL DML при выполнении определенного количества заданий. Новости сайта§ Новая задача от inkerman выставлена на третьем этапе под номером 143 (предварительная оценка сложности 3 балла). § Написал FAQ на две задачи, которые постоянно вызывают вопросы - 2 и 40. Первая уже выложена, вторая появится в ближайшее время. § После решения собственной задачи inkerman вошел в 20-ку. Других решивших эту новую задачу пока нет. § Новые лица в сотне или вернулись в нее: § Продвинулись в рейтинге: § На промежуточном этапе появился новый лидер - zerga; лучшее время после решения 117 задач. § На этой неделе сертифицированы: § Число подписчиков - 3643 Число участников рейтинга - 11638 Число участников второго этапа - 1092 Сертифицировано на сайте - 188 Лучшие результаты (ТОР 20)
Лучшие результаты за неделю
Изучаем SQLГрафический план выполнения запросов SQL Server в действииTim Chapman (оригинал: See SQL Server graphical execution plans in action )Перевод Моисеенко С.И. Планы выполнения - один из лучших инструментов для настройки ваших запросов на SQL Server. В этой статье я остановлюсь на нескольких основных моментах в графическом плане выполнении, чтобы помочь Вам лучше понять, как SQL Server использует индексы. Я также предлагаю идеи относительно того, как сделать ваши запросы быстрее. Установка моего примераЯ должен создать таблицу, которую буду использовать повсюду в примерах, и загрузить в нее некоторые данные. Я загружу довольно большое количество данных в таблицу для того, чтобы SQL Server не только сканировал таблицу при извлечении данных. Обычно, если таблица относительно мала, SQL Server будет сканировать ее вместо того, чтобы решить использовать наилучшую комбинацию индексов, поскольку в этом случае сканирование таблицы займет меньше времени.
CREATE TABLE [dbo].[SalesHistory]
(
[SaleID] [int] IDENTITY(1,1),
[Product] [varchar](10) NULL,
[SaleDate] [datetime] NULL,
[SalePrice] [money] NULL
)
GO
SET NOCOUNT ON
DECLARE @i INT
SET @i = 1
WHILE (@i <=50000)
BEGIN
INSERT INTO [SalesHistory](Product, SaleDate, SalePrice)
VALUES ('Computer', DATEADD(ww, @i, '3/11/1919'),
DATEPART(ms, GETDATE()) + (@i + 57))
INSERT INTO [SalesHistory](Product, SaleDate, SalePrice)
VALUES('BigScreen', DATEADD(ww, @i, '3/11/1927'),
DATEPART(ms, GETDATE()) + (@i + 13))
INSERT INTO [SalesHistory](Product, SaleDate, SalePrice)
VALUES('PoolTable', DATEADD(ww, @i, '3/11/1908'),
DATEPART(ms, GETDATE()) + (@i + 29))
SET @i = @i + 1
END
Следующий оператор создает кластерный индекс на столбце SaleID для таблицы SalesHistory. Это в некотором роде произвольный выбор для кластерного индекса в таблице, но для данного примера он имеет смысл, так как SaleID будет увеличиваться при добавлении новых строк. Создание этого индекса физически упорядочит данные в таблице в порядке возрастания значений SaleID.
CREATE CLUSTERED INDEX idx_SalesHistory_SaleID ON SalesHistory(SaleID ASC)
Выполните этот оператор, чтобы включить статистику ввода/вывода для наших запросов.
SET STATISTICS IO ON
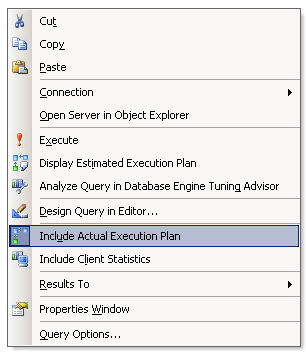
Чтобы вывести план выполнения для запросов, которые я буду демонстрировать, необходимо включить соответствующую опцию. Для этого я щелкну правой кнопкой мыши в окне редактора запросов (Query Editor) и выберу команду меню Include Actual Execution Plan. См. рисунок A. Рисунок А
 Следующий оператор выбирает строку из таблицы SalesHistory на основании значения в столбце SaleID, на котором имеется кластерный индекс.
SELECT * FROM SalesHistory WHERE SaleID = 9900
Вы можете видеть графический план выполнения и статистику для этого запроса на рисунке B. Рисунок В
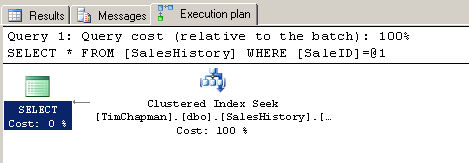 Оптимизатор выполнил поиск по кластерному индексу (Clustered Index Seek), который является технически самым быстрым типом поиска в таблице, которые Вы увидите. Обратите внимание, что было выполнено три логических операции чтения для поиска этой строки в таблице: Table 'SalesHistory'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Нижеприведенный скрипт ищет все записи в таблице SalesHistory, для которых продуктом является PoolTable. В настоящее время нет никакого индекса на этом столбце, при этом имеется только три различных значения в этом столбце для всех строк таблицы. Возможными значениями могут быть только PoolTable, Computer или BigScreen.
SELECT * FROM SalesHistory WHERE Product = 'PoolTable'
План выполнения вышеприведенного запроса показывает, что было выполнено сканирование кластерного индекса (Clustered Index Scan), поскольку для таблицы имеется кластерный индекс. Напомню, что кластерный индекс сортирует таблицу в порядке, заданном ключами индекса. В данном случае кластерный индекс реально не помогает мне, потому что все таки необходимо выполнить сканирование, чтобы найти все случаи, когда продукт равен PoolTable. См. рисунок C. Рисунок С
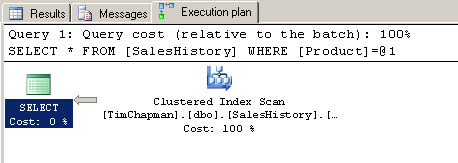
Table 'SalesHistory'. Scan count 1, logical reads 815, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Итак, что случится, если мы создадим индекс на столбце Product в таблице SalesHistory? Если Вы выполните следующий оператор создания некластерного индекса для этой таблицы, то заметите, что ничего не изменилось, даже с индексом на столбце Product. План выполнения и число логических операций чтения то же самое из-за селективности значений в столбце. Имеется только три различных значения для всех строк в этой таблице, поэтому дополнительный индекс не сможет помочь в нашем случае, поскольку требуется вытащить слишком много записей. Индексы наиболее выгодны, когда они строятся на столбцах, которые содержат много различных значений.
CREATE NONCLUSTERED INDEX idx_SalesHistory_Product ON SalesHistory(Product ASC)
(окончание следует...) Полезная информация§ Все статьи, публикуемые в рассылке, затем выкладываются на сайте Книги и статьи по SQL. § В рамках Премии Рунета проводится "народное голосование". Если вы считаете, что наш сайт заслуживает большей известности в рунете, проголосуйте за него. Для этого § Желающих поспособствовать популяризации сайта прошу проголосовать/поставить закладку в социальных сетях: КонтактыПо всем вопросам, связанным с функционированием сайта, проблемами при решении упражнений, идеями вы можете обращаться к Сергею И.Моисеенко msi77@yandex.ru. Вы также можете предложить свои задачи для публикации на сайте. |
| В избранное | ||
